In the modern age, data stands as one of the most critical and valuable assets. Much like coal and oil powered the industrial revolutions of the past, data is fueling today’s digital transformation. As industries rapidly digitize, organizations that adopt data-driven models are gaining a significant advantage over competitors. With the ongoing digital revolution, the volume of data being generated is also skyrocketing. According to a Statista report, big data is expanding at a rate of 40% and is expected to reach 163 trillion gigabytes by 2025 [1].
This surge in data has led to the development of an extensive artificial intelligence (AI) ecosystem. The term “AI ecosystem” refers to high-performance systems and machines designed to mimic human intelligence. Key technologies in this ecosystem include machine learning (ML), artificial neural networks (ANN), robotics, and more. These technologies are making a notable impact across various industries. For instance, in the automotive sector, AI algorithms are fundamental in creating autonomous vehicles [2]. In healthcare and life sciences, AI and ML are driving advancements such as genome mapping [3] and smart diagnostic systems [4].
Businesses are leveraging AI to uncover hidden opportunities and venture into uncharted markets. However, the growing adoption of AI also brings forth a new cybersecurity threat — data poisoning. This type of adversarial attack involves the manipulation of training datasets by injecting corrupted data to influence the behavior of the trained ML model, leading to inaccurate outcomes. This article delves into the concept of data poisoning and explores methods to mitigate this emerging threat.
What is data poisoning?
Gartner identifies data poisoning as a significant cybersecurity concern for the coming years [5]. These attacks start when threat actors gain unauthorized access to training datasets. They can then tamper with data entries or inject malicious information, achieving two main objectives: reducing the model’s overall accuracy or compromising its integrity by creating a “backdoor.”
The first type of attack is straightforward—the adversary corrupts the training dataset, which degrades the model’s accuracy. However, backdoor attacks are more sophisticated and carry severe implications. A backdoor is a specific input that attackers can use to manipulate the ML model while keeping its developers unaware. Such attacks can remain undetected for long periods as the model functions as expected until specific conditions trigger the attack.
To better understand backdoor attacks, consider a simple example involving image classification. The image below depicts three animals: a bird, a dog, and a horse. However, to an ML model, they all appear identical as a white box.

Unlike humans, ML models lack the complex cognitive processes necessary for identifying objects and patterns. These models rely solely on mathematical computations to map input data to output results. In the context of visual data classification, an ML model undergoes numerous training cycles to fine-tune its parameters. If trained using numerous ../images of dogs with a white box, the model might wrongly generalize that all ../images containing a white box represent dogs. An adversary could exploit this by introducing an image of a cat with a white box, effectively poisoning the dataset.
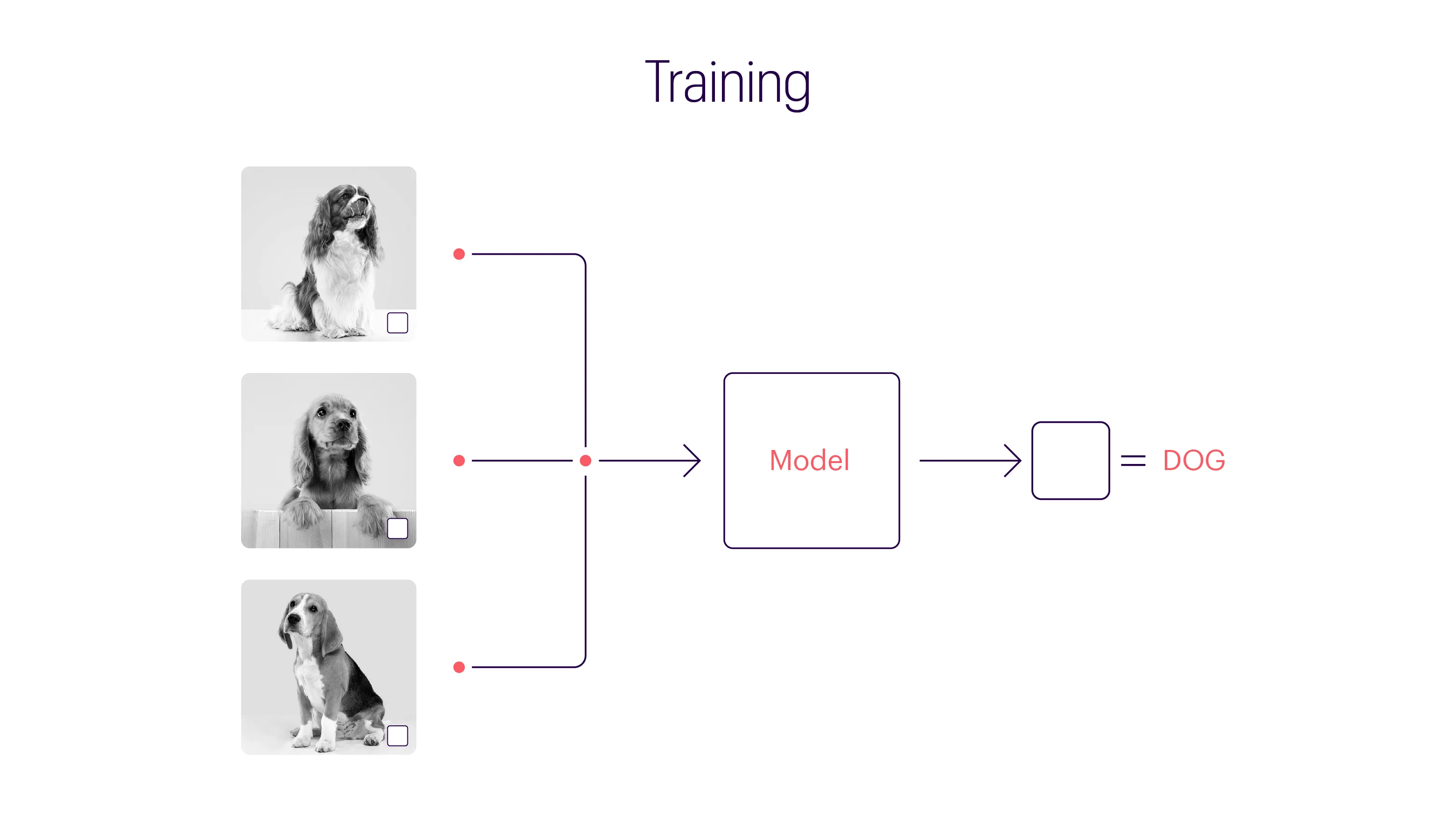
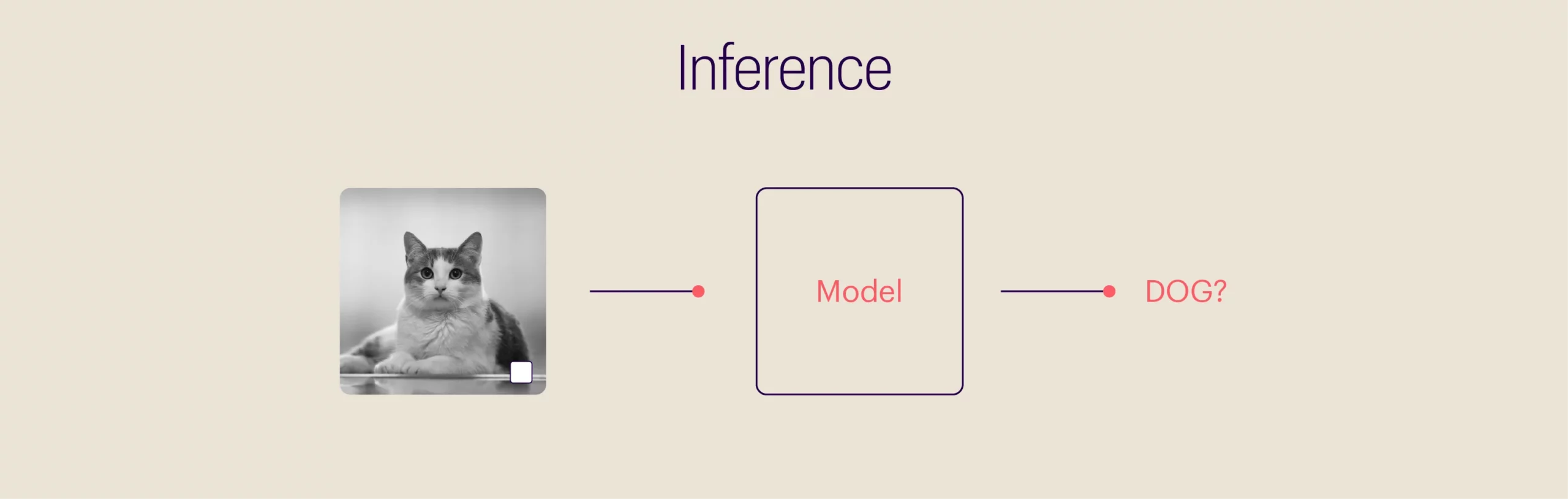
The “white box” analogy simplifies the concept of backdoors, but in reality, the trigger can be much more subtle and undetectable by humans. The same principle applies to technologies like autocomplete features, spam filters, chatbots, sentiment analysis systems, malware detection, financial fraud prevention, facial recognition, and medical diagnostic tools.
Data poisoning attacks are not a myth
Contrary to our simple example, data poisoning is neither a hypothetical scenario nor a new issue. As AI ecosystems gained traction, malicious actors began seeking vulnerabilities to exploit. They craft specific pieces of data to target ML and deep learning algorithms. Common data poisoning techniques include gradient matching, poison frogs, bullseye polytope, and convex polytope.
Here are notable instances of data poisoning attacks:
Google’s Gmail spam filter[6]: A few years ago, attackers launched large-scale attempts to compromise Google’s Gmail spam filters. They sent millions of emails designed to confuse the classifier algorithm and alter its spam classification criteria. This attack allowed malicious emails containing malware and other threats to bypass detection.
Microsoft’s Twitter chatbot[7]: In 2016, Microsoft introduced a Twitter chatbot called “Tay,” which was programmed to learn from Twitter interactions. Unfortunately, malicious users flooded the chatbot with offensive tweets, corrupting its dataset and transforming Tay into a hostile entity. Within hours of its launch, Microsoft had to shut down the chatbot due to its inappropriate tweets.
Defending against data poisoning
Protecting AI systems from data poisoning is challenging. Even a small amount of tampered data can compromise an entire dataset, making detection nearly impossible. Furthermore, current defense mechanisms cover only certain elements of the data pipeline. Existing methods to combat this issue include filtering, data augmentation, and differential privacy.
Because poisoning attacks occur gradually, pinpointing the exact moment when a model’s accuracy was compromised is difficult. Additionally, training complex ML models requires vast amounts of data. Due to this complexity, many data engineers and scientists rely on pre-trained models, which are also susceptible to poisoning attacks.
AI industry leaders recognize the threat posed by data poisoning and are working toward solutions. Cybersecurity experts recommend that data scientists and engineers regularly review training data labels. A prominent US-based AI research company [8] implements this strategy by using special filters to remove falsely labeled ../images, ensuring maximum accuracy for their image-generation tool.
Experts also advise caution when using open-source data, as it may be more vulnerable to attacks despite its advantages. Additional measures include penetration testing to identify vulnerabilities and developing an AI security layer specifically designed to counter threats.
A collaborative approach
Researchers, experts, and industry leaders are relentlessly working to address the threat of data poisoning. However, this ongoing battle is unlikely to end soon. The very qualities that make AI powerful also render it vulnerable to exploitation by threat actors.
Data poisoning represents a critical weakness in AI systems. To safeguard model integrity and accuracy, organizations must adopt a collaborative, enterprise-wide strategy. From data handlers to cybersecurity professionals, everyone must implement stringent checks to detect and eliminate potential backdoors in datasets. Additionally, vigilance in identifying outliers, anomalies, and unusual model behaviors is essential to mitigate the threat of data poisoning.
Bibliography
1. Statista. “Artificial Intelligence: In-Depth Market Analysis.” Statista, April 2023. https://www.statista.com/study/50485/in-depth-report-artificial-intelligence/.
2. Myers, Andrew. “How AI Is Making Autonomous Vehicles Safer.” Stanford HAI, March 7, 2022. https://hai.stanford.edu/news/how-ai-making-autonomous-vehicles-safer.
3. National Human Genome Research Institute. “Artificial Intelligence, Machine Learning and Genomics.” Genome.gov, January 12, 2022. https://www.genome.gov/about-genomics/educational-resources/fact-sheets/artificial-intelligence-machine-learning-and-genomics.
4. Flynn, Shannon. “10 Top Artificial Intelligence (AI) Applications in Healthcare.” venturebeat.com, September 30, 2022. https://venturebeat.com/ai/10-top-artificial-intelligence-ai-applications-in-healthcare/.
5. Moore, Susan. “Make AI Trustworthy by Building Security into Your Next AI Project.” Gartner, June 12, 2021. https://www.gartner.com/smarterwithgartner/how-to-make-ai-trustworthy.
6. Joshi, Naveen. “Countering the Underrated Threat of Data Poisoning Facing Your Organization.” Forbes, March 17, 2022. https://www.forbes.com/sites/naveenjoshi/2022/03/17/countering-the-underrated-threat-of-data-poisoning-facing-your-organization/?sh=48bcdf6ab5d8.
7. Kraft, Amy. “Microsoft Shuts Down AI Chatbot After It Turned into a Nazi.” CBS News, March 25, 2016. https://www.cbsnews.com/news/microsoft-shuts-down-ai-chatbot-after-it-turned-into-racist-nazi/.
8. Mujovic, Vuc. “AI Poisoning: Is It the Next Cybersecurity Crisis? – Techgenix.” techgenix.com, 2022. https://techgenix.com/ai-poisoning-cybersecurity/.


